|
Prof. Adolfo Bauchspiess |
|
163848 - Introdução ao Controle Inteligente
Numérico
Demo1_ICIN
Classificação
de padrões não linearmente separáveis
Objetivos:
- Introdução
aos classificadores de padrões com Redes Neurais
Artificiais.
- Verificar
que o Perceptron não resolve problemas que não são
linearmente separáveis.
- Verificar
a capacidade de classificação de diferentes topologias,
funções de ativação e algoritmos de treinamento.
Introdução:
O neurônio booleano (Perceptron)
proposto por
McCulloch e Pitts em 1943 teve caráter seminal na área de
sistemas
conexionistas. Pode, no entanto, classificar apenas padrões que
sejam
linearemente separáveis.
O X-OR foi apontado por Minsky e Pappert em
1969 como
exemplo, extremamente simples, que não pode ser aprendido pelo
Perceptron. Só
em 1986 é que Rummelhart, Hinton e Williams, mostraram que o
percetron
multicamadas com algoritmo de treinamento
"Backpropagation"
supera as dificuldades apontadas por Minsky e Pappert.
Atualmente prova-se que
que o Perceptron Multicamadas é um aproximador universal, isto
é, qualquer
função pode ser aproximada por esta rede neural artificial, com
precisão arbitrária.
Definições:
Uma Rede Neural Artificial
pressupõem:
-
Sinais de entrada, em geral denominados p - "pattern"
- Sinal de saída, y
- Sinal de saída desejada, em geral denominado t -
"target"
- Função de ativação -
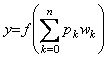
A função de ativação transforma a soma das entradas ponderadas
em um sinal de
saída, em geral limitado. As funções de ativação mais
utilizadas são: tangente
hiperbólico, sigmóide e linear.
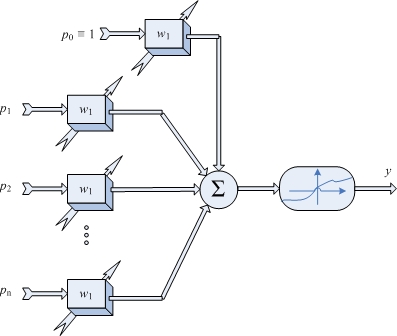
Fig. 1 Neurônio Artificial.
- Estrutura da Rede Neural Artificial:
Em uma rede neural artificial os neurônios são arranjados em
camadas. Camada de
entrada, camadas ocultas e camada de saída. De fato, a assim
chamada camada de
entrada não possui neurônios, é identica ao sinal de entrada. A
dimensão do
vetor de saída amarra o número de neurônios na camada de saída.
Assim, numa
rede com uma camada oculta, apenas o número de neurônios desta é
um parâmetro
de projeto.
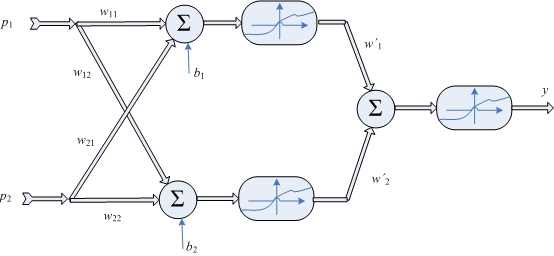
Fig. 2 Rede Neural Simples - Dois neurônios na camada oculta.
- Treinamento:
Os pesos de uma rede neural são ajustados pela contínua
apresentação dos
padrões de treinamento. A diferença entre a saída obtida e a
saída desejada
leva à alteração dos pesos, no sentido a diminuir o erro.
.Época - etapa de treinamento em que foi apresentado o conjunto
completo de
treinamento.
.Critério de parada - em raros casos o erro pode ser nulo em
redes neurais,
assim o treinamento deve ser interrompido após um número
predefinido de épocas
ou, ao se atingir um valor pré-estabelecido do erro.
.MSE - Média do Erro Quadrático
.SSE - Soma do Erro Quadrático.
Procedimento:
Considere
a
seguinte tabela verdade:
A B C
f
0 0 0 -> 1
0 0 1 -> 0
0 1 0 -> 0
0 1 1 -> 1
1 0 0 -> 0
1 0 1 -> 0
1 1 0 -> 1
1 1 1 -> 0
- Treinar
uma rede Perceptron (uma camada, newp(), função de ativação
"hardlim") para aprender f.
- Treinar
uma rede MLP (Perceptron Multicamadas, newff(), "Feed-forward
backpropagation") com algoritmo de treinamento gradiente
descendente Backpropagation, "traingd" e função de
ativação linear, "purelin", em todas as camadas. Verificar
os resultados para a 1, 2 e 3 neurônios na camada
oculta.
- Repetir
o item 2 com função de ativação logística, "logsig".
- Repetir
o item 3 com função com algoritmo de treinamento "trainlm".